
What I've Built with Kiro #1: An AI-powered portfolio that proves expertise instead of claiming it
The 6-Second Problem
Here's a number that should concern every professional: recruiters spend an average of 6-10 seconds scanning a resume before making a decision. Six seconds to evaluate years of experience, complex projects, and nuanced expertise.
The result? Resumes have evolved into keyword-optimized documents designed to survive algorithmic filtering rather than demonstrate actual capability. We've created a system where "worked on machine learning projects" and "architected and deployed production ML systems serving 10M users" look nearly identical in a quick scan.
This isn't a criticism of recruiters—they're drowning in volume and doing their best with limited time. It's a criticism of the medium itself. CVs are static, one-dimensional documents trying to represent dynamic, multi-dimensional expertise. They flatten nuanced experience into indistinguishable bullet points.
The fundamental question I asked myself: What if my portfolio could answer questions instead of just listing achievements?
The Idea: A Portfolio That Talks Back
The concept is simple but the implications are significant: instead of a static page that says "I have 15 years of experience in X," build an interactive presence that lets visitors verify that claim by asking follow-up questions.
Think about what happens in a typical hiring process: A recruiter scans your CV for 6 seconds. If keywords match, they schedule a 30-minute screening call. Then a hiring manager spends an hour verifying depth. Then comes the technical interview—2-4 hours of proving capability. That's potentially 5+ hours of human time just to verify what a candidate claims on paper. What if we could compress some of that verification into the portfolio itself?
An AI-powered portfolio can answer deep technical questions about past projects and decisions, explain the rationale and trade-offs behind architectural choices, surface relevant experience based on the visitor's specific questions, and admit knowledge boundaries honestly ("I haven't worked deeply in X").
This last point is crucial. Anyone can list "AI/ML" on a resume. Few can answer follow-up questions with nuance. The AI chatbot becomes a depth-verification mechanism disguised as a convenience feature.
Building It with Kiro: The Development Story
This project is the first in my "What I've Built with Kiro" series, where I explore how AI-assisted development is changing the way we approach software projects.
For those unfamiliar, Kiro is an AI-powered IDE that goes beyond code completion. It supports spec-driven development—you define requirements, iterate on design, break down implementation tasks, and then work through them with AI assistance. It's a fundamentally different workflow from traditional development or even from using AI as a "smart autocomplete."
Why Spec-Driven Development Matters
There's a term floating around: "vibe coding"—jumping straight into implementation, letting the AI generate code based on loose descriptions, and hoping it all comes together. It's fast and feels productive. It's also how you end up with a tangled mess that's impossible to maintain or extend.
Kiro's spec-driven approach is the antidote. Instead of "just start coding," you follow a structured progression: Vision → Requirements → Design → Tasks → Implementation.
Each step creates a checkpoint. Each checkpoint creates safety. And crucially, each document becomes context that the AI can reference throughout development.
The Progression: From Vision to Five Specs
Here's how this project actually evolved:
Step 1: Product Vision Document
Before writing a single line of code, I articulated the strategic foundation:
- Who is this for? Corporate recruiters (6-second scanners), hiring managers (depth investigators), potential collaborators (peer-level explorers)
- What problems does it solve? CV flattening, depth verification, time-to-qualify
- What principles should guide design? "Minimalist but not sterile," "Peer, not supplicant," "Honest about limitations"
- What does success look like? Visitors spending 3+ minutes exploring, 80% of chatbot questions handled coherently, inbound conversations attributed to the site
This document became the north star. Every subsequent decision could be validated against it: "Does this align with the vision?"
Step 2: The Specs
From the vision, I created five implementation specs, each building on the previous: Content Architecture (site structure, progressive disclosure, accessibility foundations) → AI Chatbot (knowledge base integration, streaming responses, conversation management) → Fit Analysis Module (job description parsing, evidence-based matching, honest gap reporting) → Transparency Dashboard (three-tier skill visualization) → Visual Design Upgrade (color system, typography, micro-interactions). Each spec contained detailed requirements with testable acceptance criteria, component designs, and correctness properties that could be verified through automated tests.
How This Prevented Chaos
Here's what spec-driven development gave me that "vibe coding" wouldn't have:
Accumulated context. Each spec referenced the vision document and built on previous specs. When working on the fit analysis module, Kiro had context about the content architecture, the chatbot's knowledge loader, and the design principles. It wasn't starting from scratch with each feature.
Clear acceptance criteria. Instead of vague "make it work" goals, there were specific, testable requirements. "THE Chatbot_Interface SHALL open within 200 milliseconds" is verifiable. "Make it fast" is not.
Consistent design decisions. The specs enforced consistency. The fit analysis module uses the same knowledge base as the chatbot. The transparency dashboard follows the same accessibility patterns as the content architecture. These weren't happy accidents—they were specified.
Reduced rework. By thinking through requirements and design before implementation, issues got caught early. The fit analysis spec's error handling section anticipated edge cases (LLM unavailable, malformed responses, rate limiting) before Kiro wrote the code to handle them.
Documentation as a side effect. At the end of the project, I had comprehensive documentation—not as an afterthought, but as a natural byproduct of the process. The specs explain not just what the system does, but why it does it that way.
The Time Investment
Did this take longer than just diving into code? Initially, yes. Writing a proper requirements document takes time. Thinking through component interfaces before implementing them takes time.
But the payoff came quickly. Features built on solid specs required less debugging, less refactoring, and less "wait, why did I do it this way?" confusion. The AI assistance was more effective because it had better context. And when I needed to extend or modify features, the specs told me exactly what constraints I needed to respect.
For a project of this scope—five major features, each with its own complexity—the spec-driven approach probably saved me 30-40% of total development time compared to the "figure it out as you go" alternative.
The Interview Process: Extracting Real Knowledge
Here's where it gets interesting. An AI portfolio is only as good as the knowledge behind it. You can't just dump a CV into an LLM and expect depth—you'll get the same shallow, bullet-point responses that make CVs problematic in the first place.
I developed an interview process using AI as a critical career coach. The prompt (translated from German):
You are now acting as a highly critical career coach and technical recruiter. Your task is to conduct an in-depth interview about a specific station in my career to build a knowledge base for my AI-powered portfolio website. Your goal: Find the "real story" behind the bullet points. We need to move from mere claims to demonstrated competence. Interview rules: 1. No praise—stay neutral, professional, and persistent 2. One question at a time—wait for my answer before drilling deeper 3. Critical drilling—if my answer is vague ("I led the team"), push back: "What did that look like exactly? What conflicts arose? What specific framework was used?" 4. "The Unflattening"—seek the situation, concrete action, measurable result, and lessons learned. Areas to explore: Hard facts & decisions (Why technology X over Y? What was the biggest mistake?), Context (What budget and resources were available? What was the biggest obstacle?), Radical transparency (What couldn't you solve? Where were your knowledge gaps?), and Psychological levers (Where did you perform best? Where were you uncomfortable? What was the real team dynamic?).
Building the Knowledge Base
Let me be honest about what this process requires: time, but not as much as you might think. Each interview session took me about 30-60 minutes per career station. For a career spanning 15+ years with a dozen significant roles, that's roughly 6-12 hours of focused interview time.
Add in time to review and refine the extracted knowledge, identify gaps where the interview didn't go deep enough, structure the information for AI consumption, and test the chatbot's responses. All told, building a comprehensive knowledge base took me about 15-20 hours over a few weeks.
Why invest this much time? Because the alternative—a traditional CV—takes maybe 4 hours to write and delivers a fraction of the value.
Depth that can't be faked. When a recruiter asks your AI portfolio "Tell me about a time you had to make a difficult technical trade-off," it doesn't give a generic STAR-method answer. It tells a specific story with real context, real constraints, and real outcomes. That level of authenticity is impossible to achieve by just feeding a CV into an LLM.
Self-awareness you can demonstrate. The interview process forces you to confront uncomfortable questions. "What couldn't you solve?" "Where did you fail?" "What don't you know?" Answering these honestly—and having your portfolio reflect that honesty—builds credibility in a way that polished marketing copy never can.
Reusable knowledge for multiple contexts. Once you've done this deep extraction, you have a knowledge base that serves multiple purposes beyond the portfolio. Preparing for interviews becomes easier—you've already articulated your experiences in detail. Writing case studies or blog posts becomes faster—the raw material is already there. Even personal reflection benefits—the process itself is clarifying.
A competitive moat. Most people won't invest 15-20 hours in their portfolio. That's precisely why doing so creates differentiation. When a hiring manager encounters a portfolio that can engage in substantive technical dialogue, it stands out dramatically from the sea of keyword-optimized resumes.
The Unflattening: Before and After
Let me show you what this process produces. Here's a typical transformation:
Before (CV bullet):
"Led cloud migration initiative for enterprise clients"
After (knowledge base entry):
"Led a team of 4 engineers migrating a legacy .NET monolith to AWS for a healthcare client. Budget was constrained (~€200k), timeline was 8 months. Chose ECS over EKS because the team had no Kubernetes experience and the learning curve would have blown the timeline. Biggest mistake: underestimated data migration complexity—we had to rebuild the ETL pipeline twice. What I couldn't solve: the client's internal politics around data ownership delayed us by 6 weeks, and I never found a good way to navigate that."
See the difference? The second version lets an AI answer follow-up questions authentically:
- "Why ECS over EKS?" → Real answer based on team capability and timeline constraints
- "What went wrong?" → Specific technical challenge (ETL pipeline) and organizational challenge (data ownership politics)
- "What would you do differently?" → Real lessons about data migration planning and stakeholder management
- "What was the team structure?" → Actual team size and composition
- "What was the budget?" → Real numbers and constraints
This isn't marketing copy. It's the messy, honest reality of how projects actually unfold. And that authenticity is what makes the AI portfolio credible.
Why This Matters
The job market is noisy. LinkedIn is full of profiles claiming "passionate about innovation" and "proven track record of success." These phrases have become meaningless through overuse. Meanwhile, recruiters are drowning in volume and hiring managers are spending hours in interviews just to verify what candidates claim on paper.
An AI-powered portfolio changes the equation for everyone.
For professionals, it's differentiation through demonstrable depth. Instead of saying "expert in cloud architecture," let recruiters ask your portfolio detailed questions and judge the answers themselves. Showing what you don't know signals confidence and self-awareness—qualities that matter in senior roles. And the positioning shifts from "please hire me" to "here's how I think, let's talk if it resonates."
For recruiters and hiring managers, it's faster, better signal. Get answers to follow-up questions before scheduling a call. Verify depth without burning interview time. A candidate whose portfolio honestly says "here's where I'm strong, here's where I have gaps" is memorable—and saves you from discovering misalignment in round 3.
The paradigm shift: Traditional portfolios say "Here's what I've done. Decide if I'm worth talking to." An AI-powered portfolio says "Here's how I think. Explore as deep as you want. Let's talk if it resonates." This flips the dynamic from "filter out" to "investigate further."
The Features: What Makes It Work
Let me walk through the key components that make this portfolio different from a traditional static site.
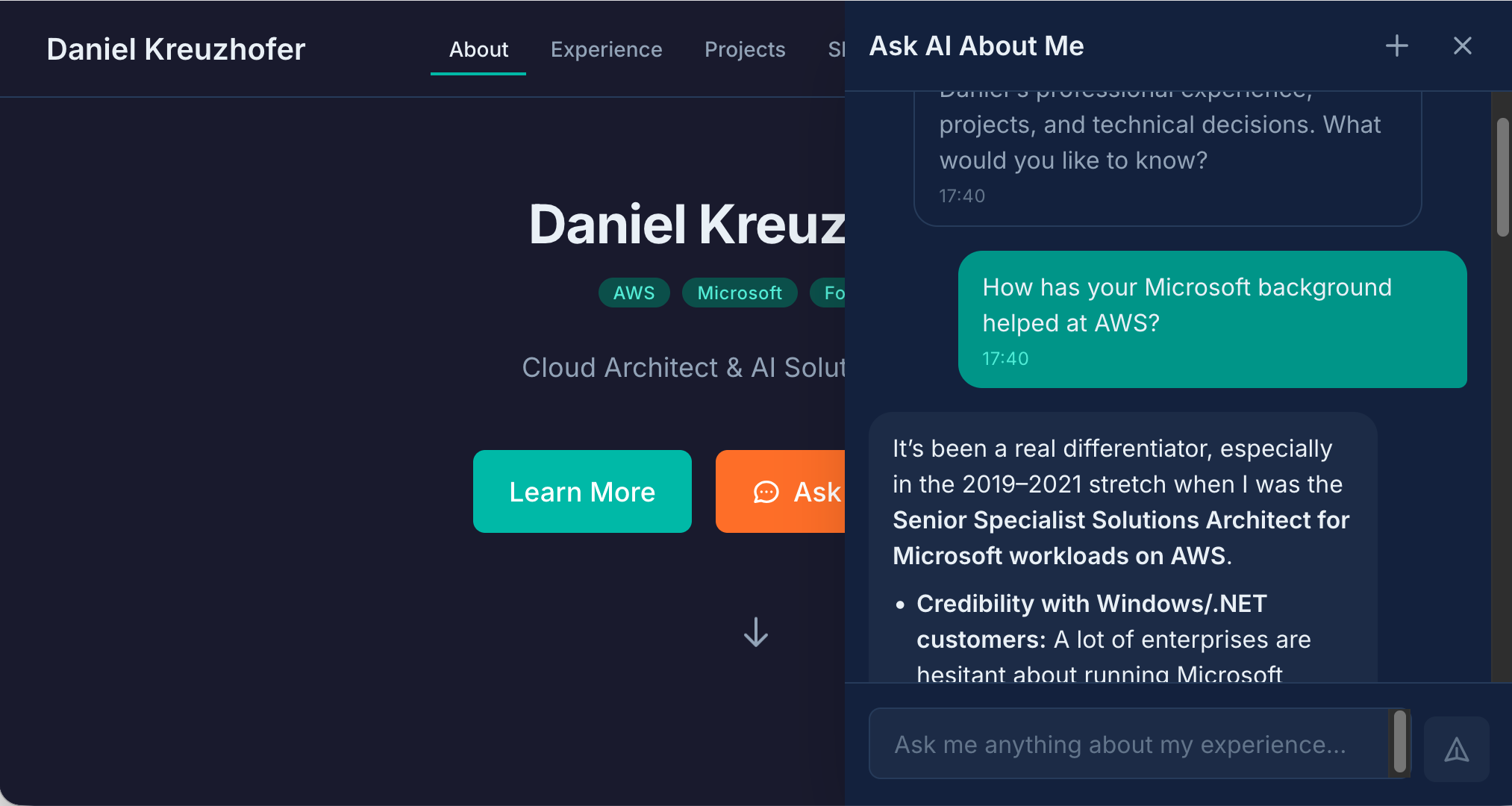
AI Chatbot: "Ask AI About Me"
The centerpiece is an AI chatbot that answers questions about my experience, projects, and expertise. This isn't a generic ChatGPT wrapper—it's grounded in a detailed knowledge base built from those interview sessions.
What it can do: Answer technical questions ("What's your experience with event-driven architectures?"), explain decisions ("Why did you choose that approach for the healthcare project?"), provide context ("What was the team size and timeline for that migration?"), and admit limitations ("I haven't worked extensively with Rust—my systems programming experience is primarily in Go.").
Why it matters: The chatbot is a depth-verification mechanism. It's easy to list technologies on a CV. It's much harder to answer nuanced follow-up questions. If the AI can engage in a substantive technical conversation, there's real knowledge behind it.

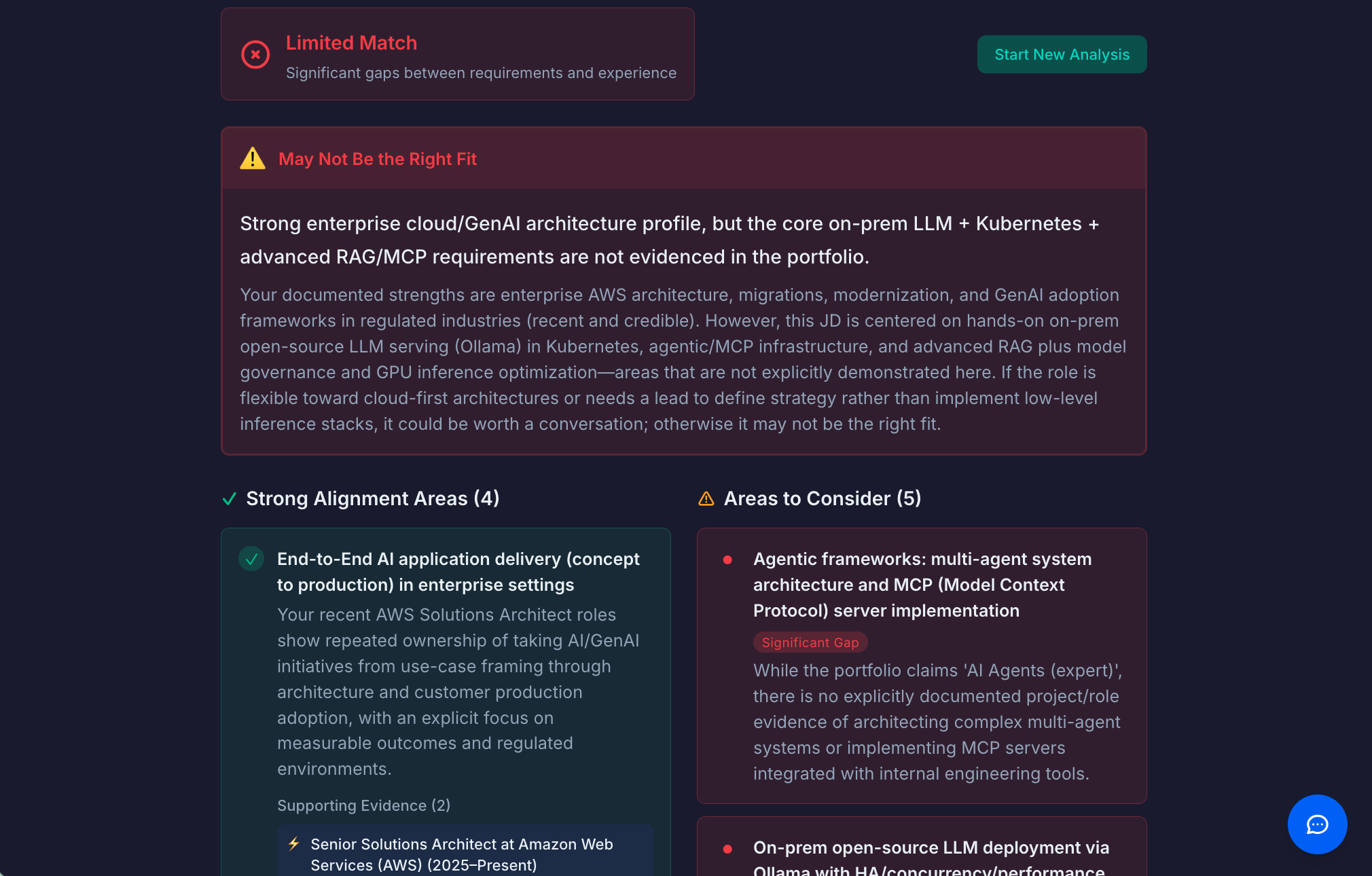
Fit Analysis Module
This feature flips the traditional application dynamic. Instead of the candidate trying to convince the employer they're a fit, the portfolio provides an honest assessment.
How it works: A visitor pastes a job description or describes a challenge. The system analyzes it against documented experience and capabilities. Then it returns an honest assessment with strong alignment areas (backed by specific evidence), potential gaps or mismatches (transparently stated), and an overall recommendation—including "this may not be the right fit" when appropriate.
Why it matters: Radical transparency builds trust. Admitting gaps signals confidence, not weakness. Recruiters remember candidates who saved them time with honest self-assessment.
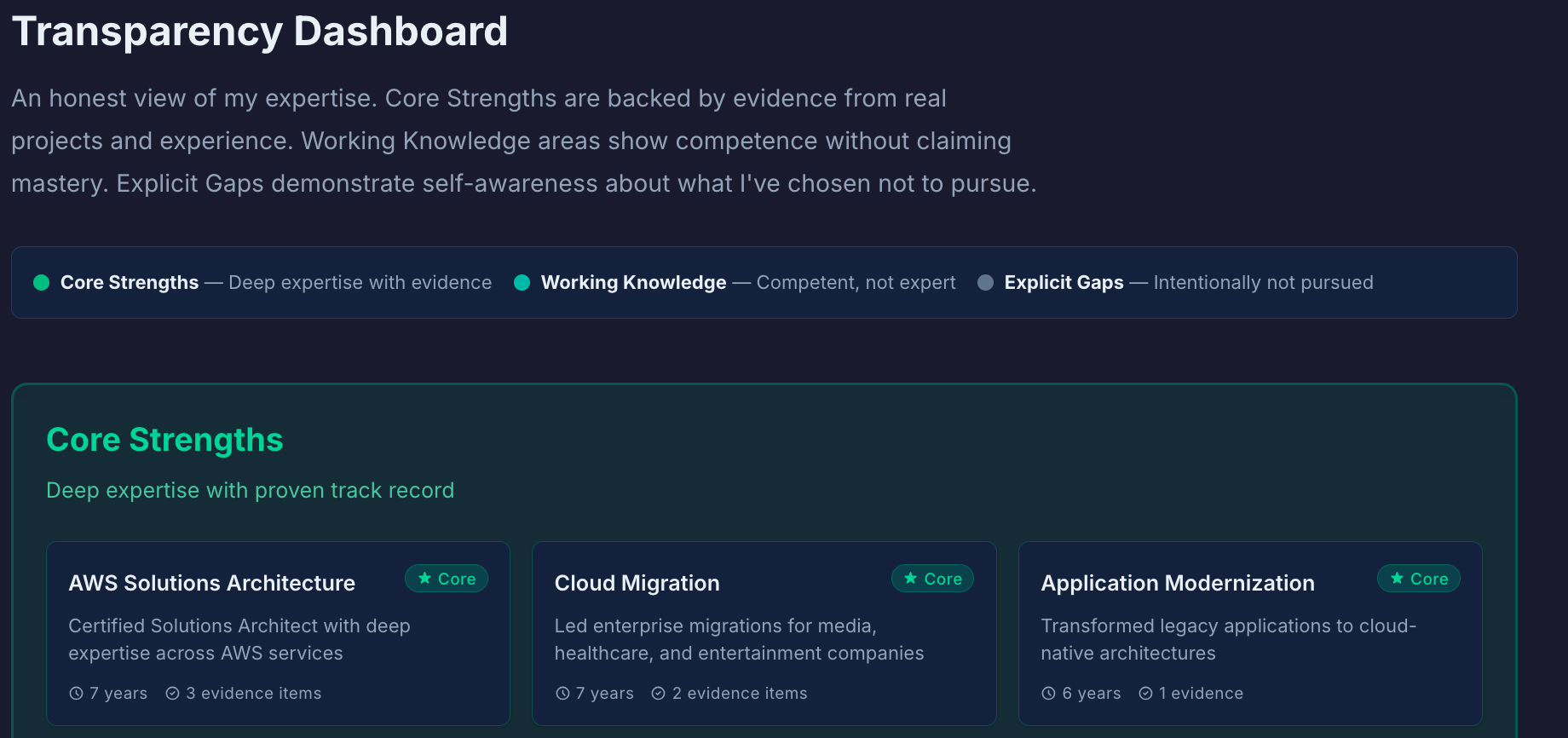
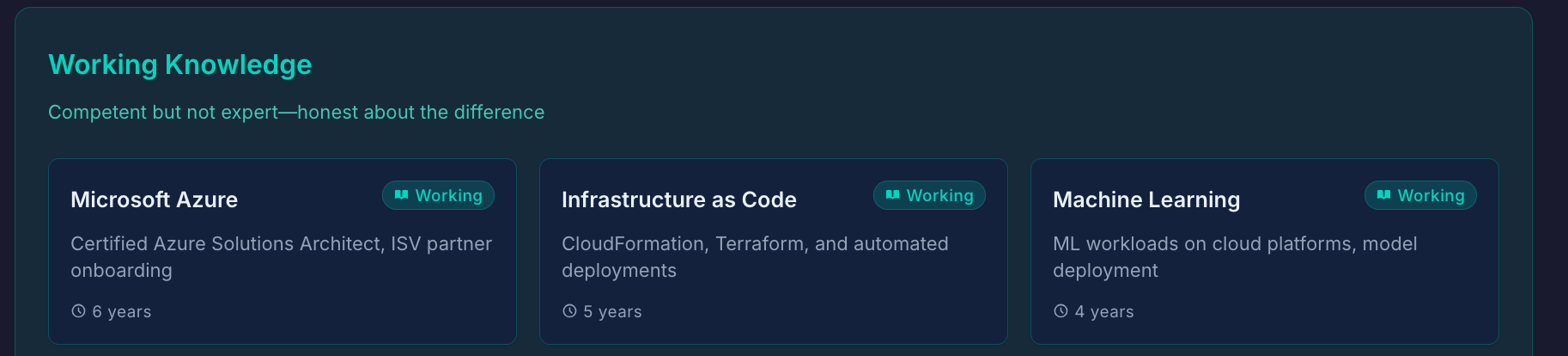
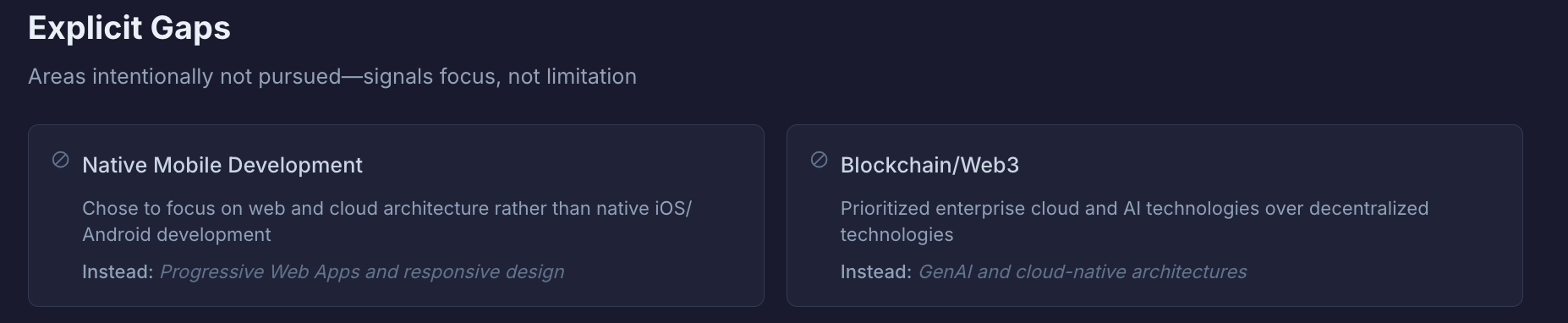
Transparency Dashboard
Most portfolios only show strengths. This one proactively shows the full picture.
The three tiers: Core Strengths (deep expertise—areas where I can lead, mentor, and make architectural decisions), Working Knowledge (competent but not expert—can contribute effectively, but wouldn't claim expertise), and Explicit Gaps (areas intentionally not pursued—signals focus, not limitation).
Why it matters: Expertise includes knowing what you don't know. This dashboard demonstrates self-awareness and intellectual honesty—qualities that matter in senior roles.

Progressive Disclosure: Respect Time, Reward Curiosity
Not everyone has the same amount of time or interest. The portfolio is designed with layers: a surface layer for the 6-second view (timeline, key skills, project titles—enough for a quick scan), expandable depth (click to reveal background stories, decision processes, lessons learned), and full exploration via the AI chatbot for unlimited depth.

Technical Deep Dive: How It's Built
The features above describe what the portfolio does. For those curious about how, here's what's under the hood.
Stack Overview
The portfolio is built with Next.js 14 using the App Router, styled with Tailwind CSS and custom design tokens, with content stored in MDX files with frontmatter metadata. The whole thing runs in Docker containers for consistent deployment.
The Knowledge Loader: Turning Content Into Context
The heart of the system is the knowledge loader—a module that reads all the MDX content files and compiles them into a format the LLM can use.
Here's what happens when someone asks a question:
The loader reads from two sources: structured MDX files (experiences, projects, skills, about) and raw markdown files in a knowledge/ directory for additional context. Each MDX file has frontmatter with structured data—not just "I led a team" but specific fields for context, challenges, decisions (with alternatives considered and rationale), outcomes (with metrics), and lessons learned.
The loader then compiles everything into prioritized context sections. About content gets highest priority (10), then experiences (9, decreasing slightly for older roles), then projects (7), then skills (6), then raw knowledge files (5). This priority system matters for future optimization—if the context gets too large, lower-priority sections can be trimmed first.
Streaming: Why It Matters and How It Works
Nobody wants to wait 10 seconds staring at a loading spinner. Streaming responses make the AI feel responsive even when generation takes time.
The implementation uses Server-Sent Events (SSE). When a user sends a message, the API route opens a streaming connection to OpenAI, then forwards each token chunk to the browser as it arrives. The frontend renders incrementally, creating the feeling of the AI "thinking out loud."
Error Handling: Failing Gracefully
LLM APIs fail in predictable ways: rate limits, timeouts, network issues, invalid responses. Each error type gets mapped to a user-friendly message that never exposes technical details or API keys.
The key principle: preserve the user's input on failure. If someone types a long question and the API times out, they shouldn't have to retype it. The failed message stays in the input field, ready to retry.
The Full Context Trade-off
I mentioned earlier that this uses "full context injection" rather than RAG (retrieval-augmented generation). For a knowledge base of ~15-20 pages, this works fine—maybe 8,000-12,000 tokens of context. The model always has access to everything, so it can make connections across different experiences and answer comparative questions.
RAG would use semantic search to find only the most relevant sections for each question, reducing token usage. But it adds complexity and can miss relevant context. For this portfolio size, full context injection is the right choice. If the knowledge base grew to 50+ pages, RAG would become necessary.
What's Next: This Is V1
I want to be clear: this is a first version. It works, it demonstrates the concept, but there's plenty of room for improvement.
What's working well:
- The chatbot handles most questions about my experience coherently
- The transparency dashboard communicates the "honest self-assessment" message effectively
- Progressive disclosure respects different visitors' time constraints
What needs work:
- The fit analysis could be smarter about parsing varied job description formats
- Mobile experience could be more polished
- The knowledge base could be deeper in some areas
What could go wrong: LLMs can still hallucinate despite guardrails—though the full-context approach and explicit boundary instructions minimize this. There's also the question of whether recruiters will actually engage with an AI chatbot, or whether it feels like a gimmick.
The Uncomfortable Question
Here's what I keep coming back to: If AI can answer questions about your experience better than your CV can, what does that say about CVs?
Maybe the resume format made sense when information was expensive to produce and distribute. You had to compress everything into one page because that's all anyone would read. But we're not in that world anymore. Information is cheap. Attention is expensive. And the ability to verify claims matters more than the ability to make them.
I'm not saying everyone needs an AI-powered portfolio. But I am saying the current system—keyword-optimized documents evaluated in 6-second scans—is failing both candidates and employers. Something has to change.
Let's Discuss
I built this because I believe the traditional CV-and-cover-letter approach is fundamentally broken for knowledge work. Static documents can't capture the depth and nuance that actually matters for senior roles.
But I'm one person with one perspective. I'd love to hear yours:
The provocative question: If you're a recruiter, would you trust an AI's assessment of a candidate's fit more than the candidate's own self-assessment? Why or why not?
For professionals: What would it take for you to invest 15-20 hours in building something like this? What's holding you back?
For hiring managers: Would you actually use a fit analysis tool, or does "radical transparency" feel like a red flag?
This is the first article in my "What I've Built with Kiro" series.
Agree? Disagree? Think I'm completely wrong about CVs? Tell me in the comments.