
What happens when you point today's best LLMs at a niche code generation problem — and what it teaches about agents, evaluation, and the path to fine-tuning
The Problem That Wouldn't Stay Solved
Here's a question I've been wrestling with for the past five months: what do you do when the frontier models — Claude, GPT-4, Grok — are genuinely impressive at general code generation but consistently fail at the one specific thing you need them to do?
In my case, the specific thing is Build123d — a Python CAD library that lets you define 3D geometry in code. Describe a spur gear, a PCB enclosure, a mounting bracket — and Build123d produces production-ready STL, STEP, and 3MF files. It's the programmatic equivalent of Fusion 360, and it's exactly what you want an LLM to generate when someone types "design a phone stand with a cable slot."
The problem? No current LLM generates reliable Build123d code out of the box. Not Claude Opus. Not GPT-4. Not Grok. They hallucinate class names that don't exist. They pass arguments in the wrong order. They call constructors with parameters that were removed two versions ago. They produce code that looks reasonable but generates empty geometry or crashes the CAD kernel.
This isn't a failure of the models. It's a data problem. Build123d is a niche library with a small open-source footprint. The models never saw enough examples during pre-training to develop reliable intuitions about how the API works. They can write excellent Python. They can reason about 3D geometry. But the specific mapping from "design intent" to "correct Build123d code" falls into a gap in their training data.
I built Chat3D to solve this problem. And what started as a fairly straightforward chat-to-CAD app became a deep exploration of how far you can push agent-based systems to compensate for gaps in model knowledge — and where those systems ultimately hit a ceiling that only model training can break through.
Attempt 1: Just Prompt It Better
Like most people, I started simple. Two-stage pipeline: a conversation LLM decides if the user wants a 3D model, then a code-generation LLM produces the Build123d code. Stuff some API documentation into the system prompt. Ship it.
The results were... mixed. Simple shapes worked. A box with rounded edges? Fine. A cylinder with a hole? No problem. But the moment complexity increased — a gear with specific tooth geometry, an enclosure with screw standoffs, a bracket with precise mounting holes — the failure rate climbed fast.
The typical failure mode wasn't spectacular crashes. It was subtle wrongness. The code would run. The rendering service would produce geometry. But the geometry wouldn't match the prompt. Wrong dimensions. Missing features. A "gear" that was actually a cylinder with some decorative bumps. And because the output looked like it worked — valid Python, no runtime errors, a 3D file you could download — it was hard to catch without visual inspection.
I tried the obvious fixes: longer system prompts, more API examples, structured output formats, explicit instruction about common mistakes. Each improvement helped at the margins but didn't change the fundamental dynamic. The model was guessing at Build123d idioms instead of knowing them.
Attempt 2: Build an Agent Around It
This is where things got interesting — and where I think the project became less about 3D printing and more about a general pattern for applying LLMs to niche domains.
If the model doesn't reliably know the API, give it tools to verify its own output. If it generates wrong code, let it see the error and try again. If it doesn't know the right class to use, let it search for examples. Build a feedback loop where the model can correct itself.
The pipeline I ended up with is significantly more complex than "prompt an LLM and render the output":
Spec generation. Before any code is written, an LLM analyzes the user's prompt and produces a structured specification: an interpretation of what to build, a verification checklist (3–6 yes/no questions like "does the model have exactly 3 holes?"), dimensional assertions (e.g., "width should be 50mm"), and a complexity classification. This specification becomes the contract that everything downstream evaluates against.
Technique research. The prompt gets decomposed into Build123d techniques (fillet, boolean cut, extrude, loft). Each technique triggers a semantic search across two knowledge bases: a library of approved workbench examples (curated, validated code), and an external knowledge base of Build123d documentation, tests, and community examples I've crawled and indexed. The results become few-shot examples injected into the code generation context.
Agent-based code generation. The agent operates in a tool-use loop with access to a virtual filesystem, a code validator, a rendering service, example and knowledge search, and API reference lookup. The agent decides its own workflow: write code, validate, fix issues, render, inspect the result, iterate. The tool loop is the fix loop — there's no separate retry mechanism. If the code doesn't validate, the agent sees the error and edits. If the rendering fails, the agent sees the error classification and adjusts.
Multi-agent decomposition. For complex prompts, a decomposition LLM splits the task into independent components. Sub-agents handle each component in isolation, then an assembly agent combines them. This prevents the "everything tangled together" failure mode where fixing one part breaks another.
Multi-track evaluation. After rendering, three independent evaluation tracks score the result: code assertions check dimensional accuracy deterministically (free, no LLM cost), a code review LLM validates parameter accuracy and feature completeness (cheap), and a VLM evaluates multi-angle screenshots against the original prompt (expensive but catches visual issues code review can't). Scores combine with adaptive weighting. If the VLM is uncertain about a checklist item, it can request zoom follow-ups — high-resolution re-renders of specific regions.
That's a lot of machinery. And it works — significantly better than the naive two-stage approach. The agent can recover from mistakes the model makes on its first attempt. The few-shot examples compensate for the model's lack of Build123d training data. The evaluation pipeline catches failures that would otherwise reach the user.
But here's the honest assessment: it's compensation, not solution.
The Data Flywheel: Why I Built a Workbench
The agent pipeline improved generation quality, but it also made something painfully visible: the same types of errors kept recurring. The model would misuse the same API patterns, make the same geometric mistakes, fail in the same ways across different prompts. The agent would fix them — burning tokens and time on every single generation — but the underlying model never learned.
This observation led to the most research-intensive part of the project: the workbench.
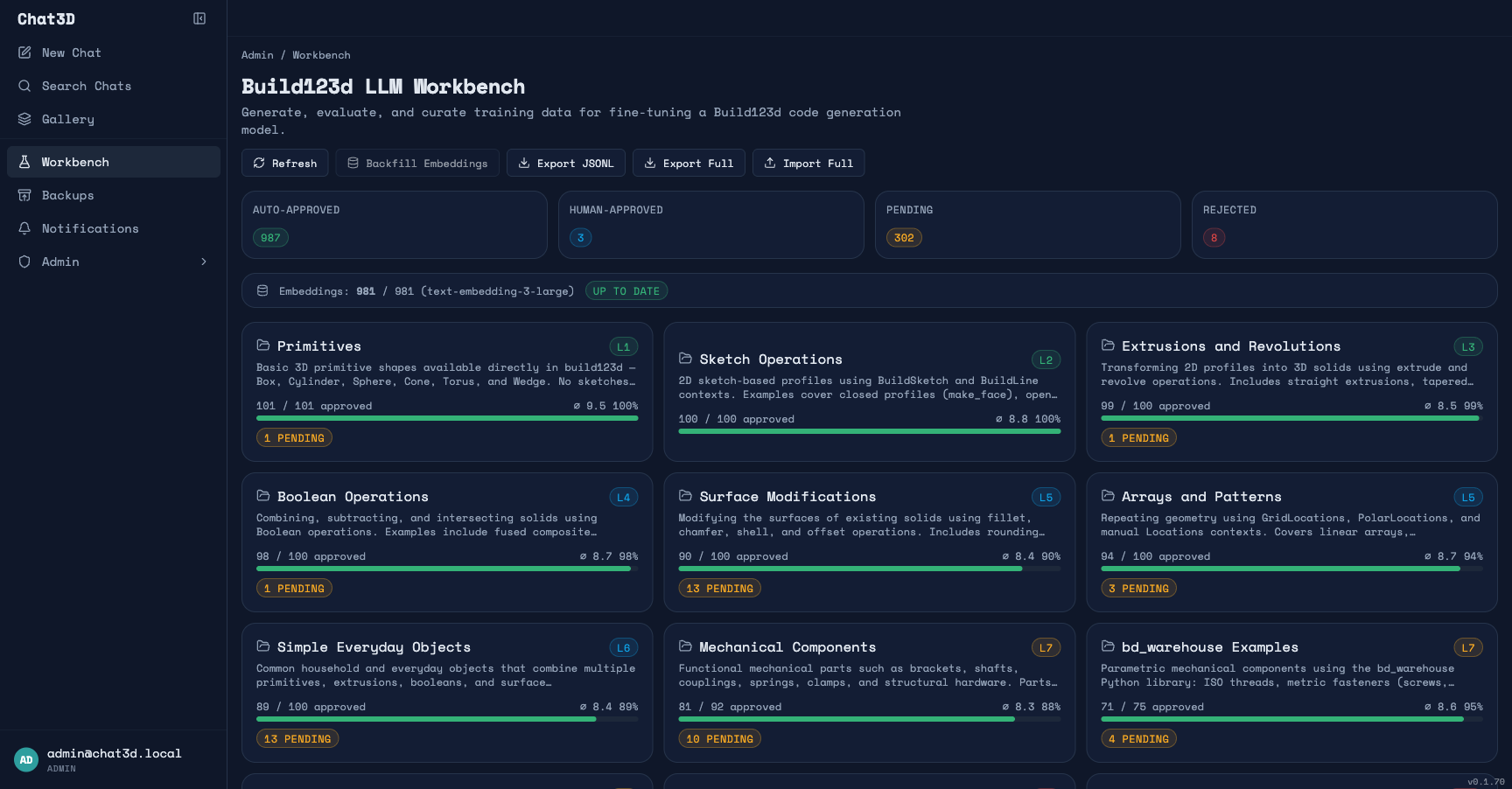
The workbench is an admin tool for generating, evaluating, and curating a training dataset. The idea is to create a data flywheel: use the agent pipeline to generate examples at scale, evaluate them automatically, curate the best ones, and eventually use them to fine-tune a model that needs less of this scaffolding — how much less is what I intend to find out.
1,100 curated prompts across 11 complexity categories, from basic primitives to complex PCB enclosures. Each prompt describes a 3D object from a user's perspective — no code hints, no API references. The categories form a complexity curriculum:
| Category | Examples |
|---|---|
| Primitives (complexity 1) | "Create a rounded cube 30mm on each side" |
| Boolean Operations (4) | "Design a plate with 4 counterbored mounting holes" |
| Mechanical Components (7) | "Create a spur gear with 24 teeth, module 2" |
| PCB Cases (10) | "Design an enclosure for a Raspberry Pi 4B with ventilation" |
For each prompt, the pipeline runs the full agent codegen → render → multi-angle screenshot → VLM evaluation → auto-approval flow. Examples scoring above threshold with passing checklists are auto-approved. Everything else gets flagged for human review.
The auto-approved examples become the few-shot retrieval corpus. As the corpus grows, the quality of new generations improves — because the agent has more and better examples to draw from. That's the flywheel: generate → evaluate → approve → inject into future context → generate better.
I also built a curation pipeline for the chat side. When a user rates a generation positively or downloads the result, that conversation becomes a curation candidate. Admins can review it, distill the prompt, tag it, and promote it to the workbench library. User behavior feeds the training data.
And I built an experiment framework so I can actually measure whether any of this is working. Experiments select a set of prompts, run them through the full pipeline with different LLM models, and produce side-by-side comparisons: eval scores, cost, generation time, failure rates. This is how I benchmark whether a prompt change, a system prompt revision, or a different model actually improves output quality — not vibes, not "it seems better," but quantified comparison across hundreds of prompts.
What This Actually Teaches About Agents
Five months of building this system has given me a perspective on LLM agents that I don't see discussed often enough. The hype cycle treats agents as the answer. In practice, they're the workaround.
Agents compensate for model knowledge gaps at the cost of tokens and latency. Every tool call, every retry, every search query is the agent doing work the model would handle instantly if it had better domain knowledge. The pipeline burns significantly more tokens per generation than a single LLM call would — because the model needs multiple attempts, needs to search for examples, needs to validate its own output. That's expensive.
The evaluation problem is as hard as the generation problem. You can't just generate code and hope it's correct. You need a multi-track evaluation system — and each track has its own failure modes. Code assertions catch dimensional errors but miss visual ones. VLM evaluation catches visual problems but can't verify precise measurements. Code review LLMs are cheap but occasionally wrong. Getting the composite score right — the weighting, the disagreement handling, the adaptive logic — took weeks of iteration.
Agent scaffolding has diminishing returns. The first few additions — error recovery, few-shot examples, pre-render validation — produced dramatic quality improvements. But each subsequent addition produced smaller gains. You hit a ceiling: the model's fundamental understanding of the domain is the bottleneck, and no amount of tooling around it changes that. A model that truly understands Build123d wouldn't need domain-specific lint rules, a composable multi-section system prompt, and a knowledge base search. It would just write correct code.
Semantic search over curated examples is unreasonably effective. Embedding approved examples and retrieving them with operation-aware re-ranking improved generation quality more than any other single change. The model doesn't know Build123d, but if you show it three examples of code that does similar things, it learns very fast in-context. This observation became the seed of the thesis I'll get to shortly.
The Experiment That Changed My Thinking
I built the entire pipeline around Claude Opus 4.6 — Anthropic's most capable model, the one you'd instinctively reach for on a difficult code generation task. And it works well. But recently I ran head-to-head experiments across four models to see how much the model actually matters in this pipeline, and the results challenged some of my assumptions.
The experiment: 20 prompts sampled across 10 complexity categories, each run through the full pipeline with four different code generation models. An important detail: each pipeline stage has its own model assignment. Spec generation, code review, VLM evaluation, and embedding search all used the same models across every run — only the codegen model was swapped. This isolates the variable: same evaluation, same research, same spec analysis — only the model writing the actual Build123d code changes.
Here are the numbers:
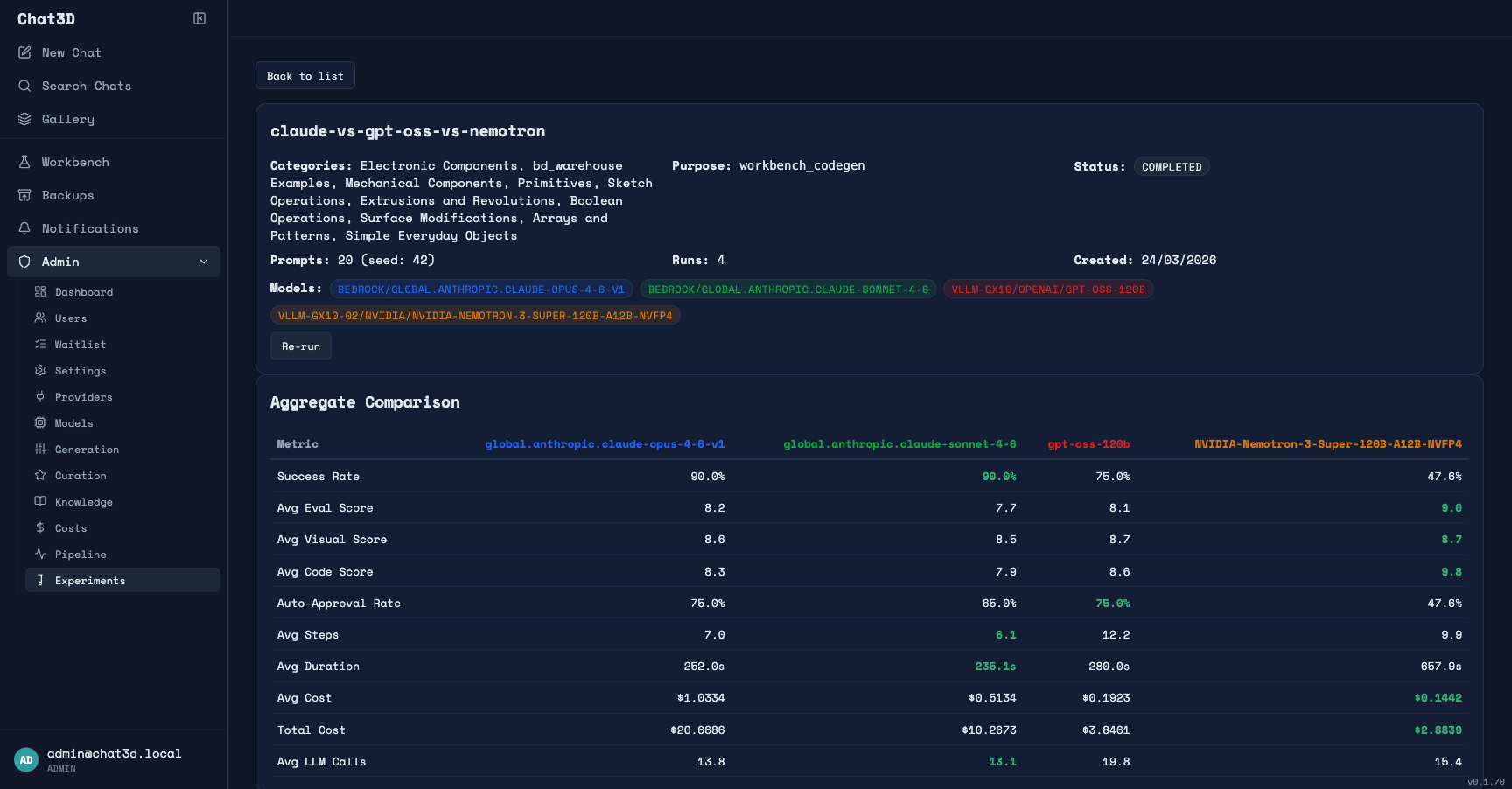
| Claude Opus 4.6 | Claude Sonnet 4.6 | gpt-oss-120b | Nemotron-120B | |
|---|---|---|---|---|
| Avg eval score | 8.2 | 7.7 | 8.1 | 9.0 |
| Avg code eval | 8.3 | 7.9 | 8.6 | 9.8 |
| Avg visual score | 8.6 | 8.5 | 8.7 | 8.7 |
| Success rate | 90% | 90% | 75% | 48% |
| Auto-approval rate | 75% | 65% | 75% | 48% |
| Cost per generation | $1.03 | $0.51 | $0.19 | $0.14 |
| Avg agent steps | 7.0 | 6.1 | 12.2 | 9.9 |
| Avg duration | ~4 min | ~4 min | ~5 min | ~11 min |
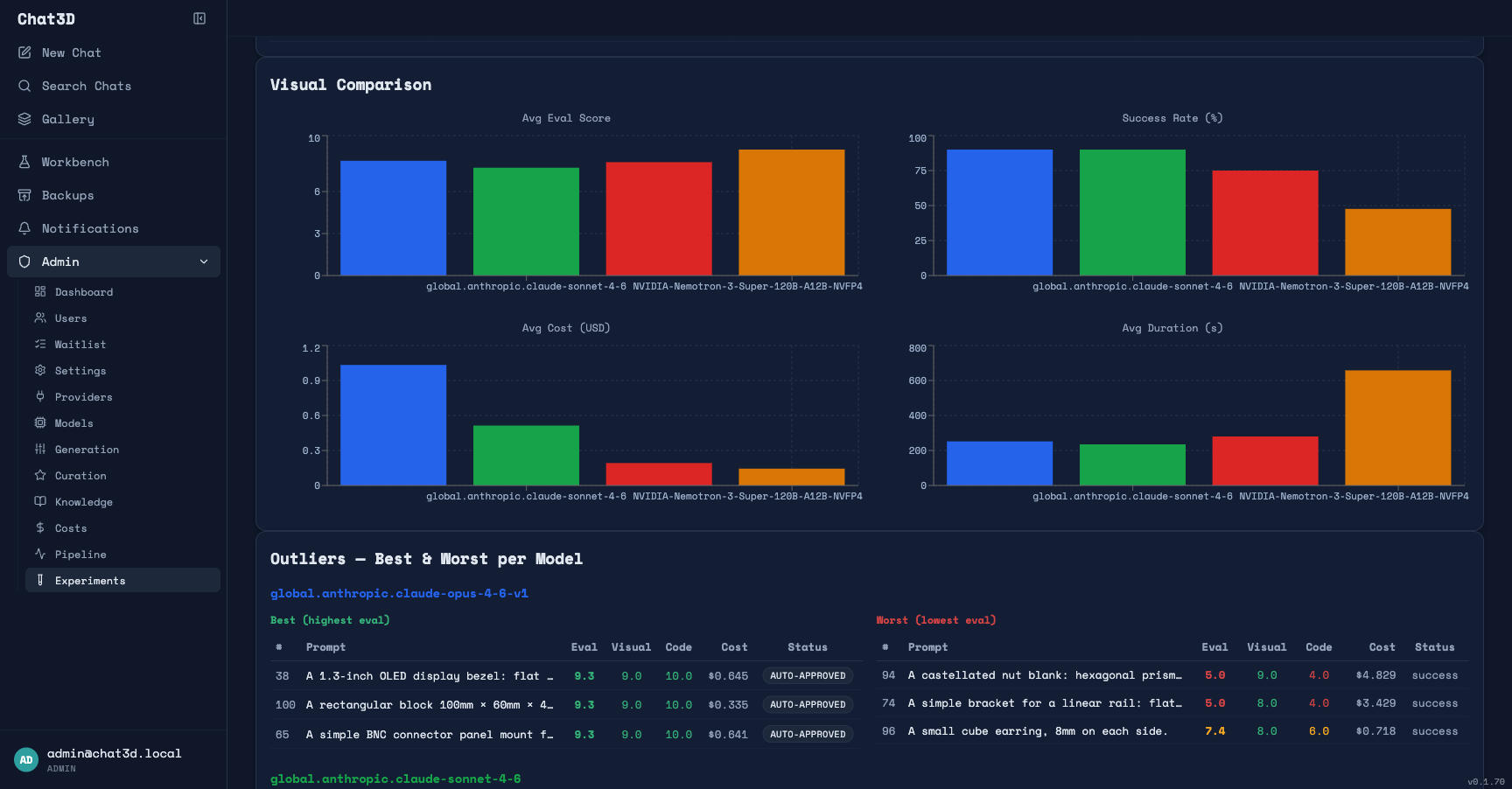
Let me unpack what's happening here, because the headline numbers are misleading without context.
Opus barely beats Sonnet. The most expensive model in the test (Opus at $1.03 per generation) scores only 0.5 points higher than Sonnet at half the price. Both have identical 90% success rates, identical visual scores. On a niche domain like Build123d, Opus's additional general intelligence barely registers. This was the first signal that the domain is the bottleneck, not model capability.
gpt-oss-120b matches Opus on quality — when it succeeds. gpt-oss-120b scored 8.1 — essentially matching Opus's 8.2 — at roughly one-fifth the cost. Its success rate is lower (75% vs 90%), but look at what's happening under the hood: it takes 12.2 agent steps on average versus Opus's 7.0. The pipeline is working harder to compensate for the model's weaker first-pass accuracy. When the agent succeeds in scaffolding the model to a correct result, the quality is right there. And the auto-approval rate — which measures examples that pass automated quality thresholds — is identical to Opus at 75%.
Nemotron is the most interesting result. When Nemotron succeeds, it produces the highest quality outputs of any model tested — avg eval score of 9.0, code eval of 9.8. Higher than Opus. At one-seventh the cost. But its success rate is only 48%. The primary failure mode isn't quality — it's pipeline timeouts. Nemotron averages 11 minutes per generation, and when it exceeds the pipeline's time limits, the generation counts as a failure regardless of whether it was converging on a good result. In a future experiment I'll remove the timeout constraints and give it the time it needs. I suspect the success rate will climb significantly — and the quality advantage will hold.
The critical observation: On this niche domain, model size and general capability matter far less than you'd expect. Sonnet nearly matches Opus. A 120B open-weight model matches Opus on quality at a fraction of the cost. And Nemotron — also 120B — exceeds Opus quality when the pipeline doesn't time it out. The models are all limited by the same thing: insufficient Build123d training data. The frontier model's advantage in general intelligence doesn't compensate for this gap.
The Thesis: Domain Training Beats General Intelligence on Niche Tasks
These experiment results lead to a thesis I'm now trying to prove:
On a sufficiently niche domain, a smaller model fine-tuned on domain-specific data should outperform frontier models running behind complex agent scaffolding — at a fraction of the cost.
The evidence points strongly in this direction. Here's why I believe it:
If Opus 4.6 — the most capable general-purpose model available — scores only marginally better than models a fraction of its size on Build123d code generation, then general intelligence isn't the differentiator. The bottleneck is domain knowledge. All four models are guessing at Build123d patterns with roughly equal success, because none of them saw enough Build123d code during pre-training.
Fine-tuning changes this equation directly. Instead of compensating for missing knowledge with agent loops, few-shot retrieval, and multi-track evaluation, you put the knowledge into the model's weights. The model stops guessing and starts knowing.
The few-shot evidence reinforces this. When I show any of these models three semantically similar examples in context, generation quality jumps dramatically. Few-shot is learning at inference time, from 3 examples, stuffed into a context window. Fine-tuning is the same learning, but from 10,000 validated examples, burned into the weights permanently. If three in-context examples produce this much improvement, what happens when the model has internalized thousands?
Here's what I expect fine-tuning gpt-oss-120b on the workbench dataset to demonstrate:
- Higher first-pass accuracy. The model should get it right on the first attempt more often. Agent steps should drop from 12 to something closer to 3–5 — or even 1.
- Higher success rate. The 75% success rate of the base model reflects the agent hitting limits while trying to fix domain knowledge gaps. If the knowledge is in the weights, there's less to fix.
- Quality that matches or exceeds Opus. The base model already matches Opus at 8.1 when it succeeds. With domain training, I expect it to surpass frontier models consistently — because it has something they don't: deep familiarity with the specific domain.
- Lower cost per generation. Not just from cheaper inference, but from a potentially simpler pipeline. If the model needs fewer agent steps, less technique research, and less knowledge base context to produce correct code, each of those reductions compounds. How much simpler the pipeline can get is an open question — but the experiment framework will measure it directly.
The workbench already produces training data in LLaMA-Factory JSONL format. The plan is to fine-tune gpt-oss-120b with LoRA on a target of 10,000 approved examples — the dataset the workbench pipeline is generating right now. The experiment framework will measure the before and after directly: same prompts, same evaluation criteria, scaffolded pipeline with base model versus fine-tuned model with simplified pipeline. Quantified, not vibes.
I don't know yet how much of the pipeline I'll be able to simplify. Maybe fine-tuning means fewer agent steps but you still need validation and evaluation. Maybe it means the agent loop barely fires at all. Maybe some pipeline stages become unnecessary while others remain essential. That's exactly what the experiment framework is designed to measure — re-run the same prompts, same evaluation, and compare the fine-tuned model against the baseline to see where the needle actually moves.
The Context Window Question: More Examples, Better Results?
There's a related question I haven't answered yet: does stuffing more few-shot examples into the context window keep improving results? And if so, where's the ceiling?
Right now, the pipeline retrieves up to 6 semantically similar examples per generation. That's a design choice, not a proven optimum. Maybe 3 examples is enough. Maybe 12 would be significantly better. Maybe there's a sweet spot after which additional examples just add noise — or hit the well-documented "lost in the middle" problem where models pay less attention to content buried deep in a long context.
I'm extending the experiment framework to test this directly. The next round of experiments will vary the number of few-shot examples as an independent variable — 0, 1, 3, 6, 10, maybe more — while holding the model and everything else constant. This gives me a quality-versus-context curve: how much does each additional example improve generation quality, and where do the returns flatten?
This matters for the fine-tuning thesis because it directly measures what context is compensating for. If going from 3 to 10 examples produces a meaningful quality jump, that's evidence the model is learning a lot at inference time from each additional example — and that same learning should be even more effective when burned into the weights via training. If quality plateaus at 3 examples and more context doesn't help, that tells a different story: maybe the model's ability to leverage in-context examples has a ceiling, and fine-tuning is the only way past it.
Either way, the answer informs how much of the pipeline a trained model can simplify.
There's also an interesting economic dimension here. Large context windows are a genuine innovation — I wouldn't have gotten this far without them. But it's worth noting that context and training are to some degree substitutes. My current pipeline sends 8,000–15,000 tokens of system prompt, API reference, and retrieved examples with every codegen call. If a fine-tuned model could produce the same quality with significantly less context — because the patterns are in the weights rather than the prompt — that changes the cost structure meaningfully. Input tokens drop, latency drops, and the retrieval infrastructure gets simpler.
This isn't a criticism of how providers build or price their models — larger context is strictly more capable, and prompt caching already helps reduce costs on repeated context. But from a research perspective, it raises a question worth investigating: for a given domain-specific task, what's the optimal split between knowledge-in-the-prompt and knowledge-in-the-weights? That's the question my experiments are designed to answer, and the results should be interesting regardless of which side they favor.
The experiments I'm planning will quantify both sides: how much quality does additional context buy, and how much of that can training internalize? That's the data needed to make an informed architecture decision for any domain-specific AI application.
But here's what makes all of this more than a personal project: the methodology generalizes.
The problem I'm solving isn't unique to 3D CAD. It's the same problem every team faces when they try to use LLMs on a domain with limited training data. Legal document generation with specific clause libraries. Medical coding with ICD-10 specificity. Infrastructure-as-code for niche cloud platforms. Regulatory compliance filings. Any domain where the models are almost good enough but fail on the specifics.
The pattern is:
- Build an agent pipeline that compensates for model knowledge gaps
- Use the pipeline to generate and evaluate examples at scale
- Run experiments to confirm that the domain — not model capability — is the bottleneck
- Fine-tune a smaller model on the curated dataset
- Re-evaluate with the same experiments to measure what changed
Steps 1–3 are what I've built and validated. Steps 4–5 are what's next. And I think this progression — from agents to data to evidence to training — is the path most serious AI applications will eventually follow. The question isn't whether your domain needs a fine-tuned model. It's whether you're building the infrastructure to find out.
A Note on How This Was Built
Something I want to be transparent about: the entire codebase was built with AI coding tools — primarily Claude Code, using the engineering rules and spec-driven workflow I described in my previous articles.
That's worth pausing on, because it shapes how you should think about this project. The code is the artifact — AI wrote it. What matters is the architecture: which pipeline stages to build, how they compose, what to evaluate and how, what data to capture and in what format. Those design decisions came from iterating on the problem for five months, watching where the pipeline failed, and building the next piece of infrastructure to address it.
A single developer, evenings and weekends, produced a system with a 5-stage generation pipeline, 3-track evaluation, a 1,100-prompt complexity curriculum, a data flywheel from chat to curation to training dataset, and an experiment framework for benchmarking models against each other. That's the real story about AI-assisted development: the bottleneck has shifted from "can I write the code?" to "do I understand the problem well enough to design the system?"
The code will be rewritten, refactored, probably thrown away. The architecture — the insight that you need spec generation before codegen, that evaluation needs multiple independent tracks, that user behavior should feed training data — that's the durable contribution.
What I'd Do Differently Starting Today
If I were starting this project over with what I know now, I'd change the order of operations.
Build evaluation before generation. I spent weeks improving the generation pipeline before I could reliably measure whether it was improving. That's backwards. The experiment framework and multi-track evaluation should have been day one. You can't improve what you can't measure, and in a domain where "looks right" is dangerously misleading, automated evaluation isn't optional — it's the foundation everything else builds on.
Design for training data from the start. I retrofitted the curation pipeline and JSONL export onto an existing system. It works, but the architecture would be cleaner if every generation had been designed to produce a potential training example from the beginning. The prompt, the validated code, the evaluation scores — capture it all, every time.
Start scaffolding, but design for re-evaluation. Agent pipelines are the right first step. But design each stage so it can be independently measured and potentially bypassed. If your spec generation is tightly coupled to your codegen, you can't test whether a fine-tuned model still needs it. Build the stages as independent components with their own metrics — so you can re-run the same experiments after training and see which stages still earn their keep.
Let's Discuss
I'm sharing this because I think the "agents versus training" conversation is too often framed as either/or. In practice, it's a progression: agents first (compensate for model gaps), then data (capture what works), then training (close the gap permanently). Most teams I talk to are stuck at step 1, building increasingly complex agent scaffolding without a plan for what comes after.
The provocative question: If a 120B open-weight model already matches Opus on quality at one-tenth the cost — just with more agent iterations — how much of the current "you need frontier models" narrative is actually true for domain-specific work? And how much is just insufficient training data?
For AI engineers: Are you seeing the same pattern in your domain — frontier models barely outperforming smaller ones because the bottleneck is domain knowledge, not general capability? I'm curious whether this finding generalizes.
For technical leaders: If the experiment data holds, the implication is clear: on niche domains, investing in training data and fine-tuning a smaller model may be more effective than paying 10x for a frontier model behind complex scaffolding. How are you thinking about this trade-off?
The project is live at chat3d.app. I'll share fine-tuning results when I have them — including honest numbers on quality delta, cost reduction, and which parts of the pipeline a trained model changes. The interesting question isn't whether training improves quality (the experiment data already suggests it should). It's where exactly the improvement lands — fewer agent steps? Higher first-pass accuracy? Less need for few-shot context? — and what that tells us about the economics of domain-specific AI.